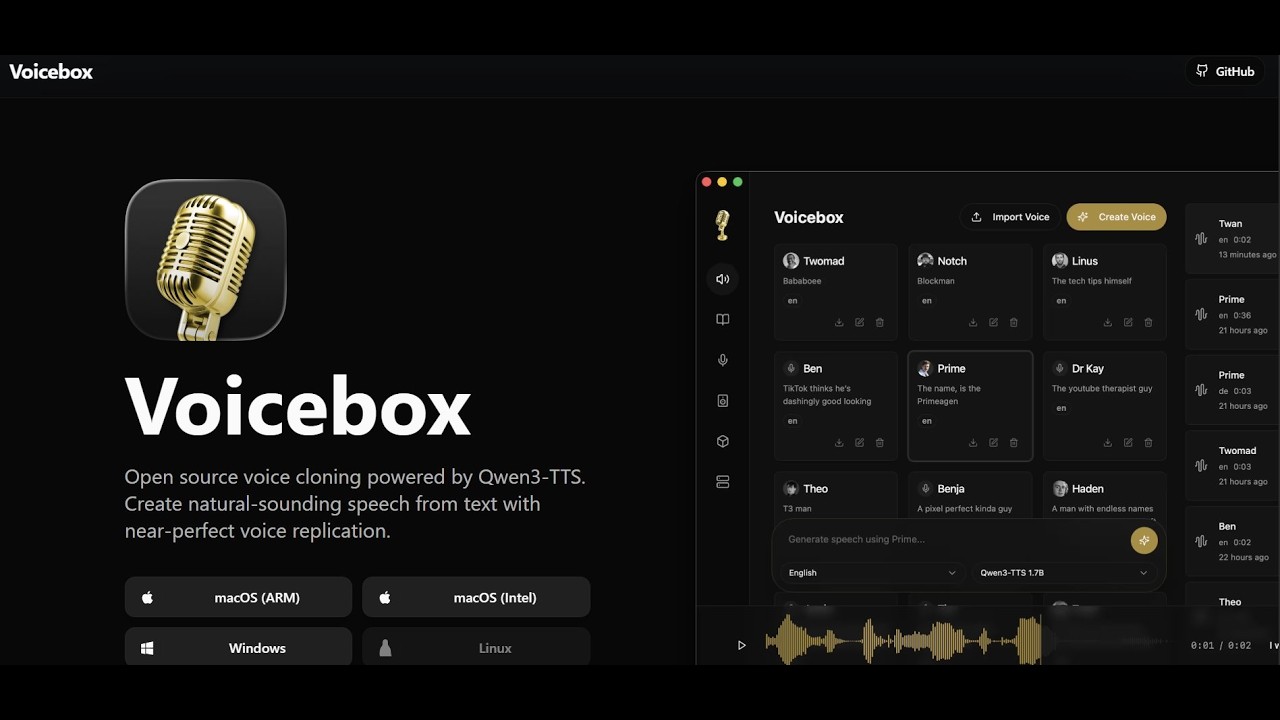
Clone, dictate and create.
Clone voices, generate speech across seven TTS engines, dictate into any app, and talk to agents in voices you own. A free and local alternative to ElevenLabs and WisprFlow, running entirely on your machine.
macOS, Windows, Linux
Alexander AI Voice
Get your logo in front of 170k+ monthly visitors.
Alexander AI Voice is open-source and used by creators, voice artists, podcasters, writers, developers, accessibility users, and curious humans all over the world. Sponsor the project and your logo lands on the homepage, in the app, in the README, and on the sponsors page — in front of every one of them.
Professional voice tools, zero compromise
Everything you need to clone voices, generate speech, and produce multi-voice content — running entirely on your machine.
Near-Perfect Voice Cloning
Multiple TTS engines for exceptional voice quality. Clone any voice from a few seconds of audio with natural intonation and emotion.
Stories Editor
Create multi-voice narratives with a timeline-based editor. Arrange tracks, trim clips, and mix conversations between characters.
Audio Effects Pipeline
Apply pitch shift, reverb, delay, compression, and more — then save as presets. Preview effects live and set defaults per voice profile.
Local or Remote
Run GPU inference locally with Metal, CUDA, ROCm, Intel Arc, or DirectML — or connect to a remote machine. One-click server setup with automatic discovery.
Audio Transcription
Powered by Whisper for accurate speech-to-text. Automatically extract reference text from voice samples.
Unlimited Generation Length
Generate up to 50,000 characters in one go. Text is auto-split at sentence boundaries, generated per-chunk, and crossfaded seamlessly.
Any clip becomes a voice.
Three ways to get a sample in. Upload a clip, record from your microphone, or capture audio playing on your system. Alexander AI Voice clones the voice from as little as 3 seconds of audio.
Click to record from your microphone.
Maximum duration: 30 seconds.
Dictate anywhere. Paste into any app.
Hold a shortcut anywhere on your machine, speak, release. The transcript lands in a focused text field in any app, or your clipboard. Agents speak back through the same pill in any cloned voice.
Whisper, sized for every machine
Base, Small, Medium, Large, and Turbo. Pick the size that fits your hardware and quality bar — 99 languages across every tier, all running locally.
Refined transcripts
A local LLM cleans ums, self-corrections, and punctuation without rephrasing. Optional, toggleable, and never leaves your machine.
Agents speak in voices you own
Any MCP-aware agent — Claude Code, Cursor, Cline — gets a voice with one tool call. The pill surfaces when an agent is speaking, so you always see what’s coming out of your machine.
Every agent gets a voice.
One tool call — voicebox.speak— and any MCP-aware agent can talk to you in a voice you’ve cloned. Claude Code, Cursor, Cline, or anything that speaks MCP.
{
"mcpServers": {
"voicebox": {
"url": "http://127.0.0.1:17493/mcp"
}
}
}// In any MCP-aware agent:
await voicebox.speak({
text: "Deploy complete.",
profile: "Morgan",
})POST /speakfor anything that doesn’t speak MCP — ACP, A2A, shell scripts, or custom harnesses.Per-agent voice
Bind each MCP client to a voice profile. Claude Code in Morgan, Cursor in Scarlett — you know which agent is talking without looking.
Always visible
Every agent-initiated speech surfaces the pill. No silent background TTS — you always see what’s coming out of your machine.
Open protocols
MCP ships day one. ACP, A2A, and anything else built on a tool-call primitive slots into the same endpoint.
Voices with a personality.
Give any voice profile a free-form personality. Then Rewrite your text in their voice, or let them Compose a fresh line of their own — your cloned voice, in full character.
“1940s noir detective. World-weary, cynical, every situation a metaphor for the city's underbelly. Talks like he's seen one stack trace too many.”
Rewrite
Restate your text in their voice while preserving every idea. Same content, their delivery — for scripts, dubs, and consistent character voice across long-form work.
Compose
No input needed — hit the button and the character improvises a fresh line of their own. Roll again for another take. Useful for game dialogue, narration cues, or character barks.
Your local voice API
Every engine you download becomes a REST endpoint on your machine. Build apps, games, and voice tools with full programmatic control — no API keys, no rate limits, no per-character fees.
http://127.0.0.1:17493/generateGenerate speech/generate/{id}/cancelCancel a generation/profilesList voice profiles/profilesCreate a new profile/models/statusModel catalog & state/historyPast generations/healthServer healthcurl -X POST http://127.0.0.1:17493/generate \
-H "Content-Type: application/json" \
-d '{
"text": "Welcome to the game, player one.",
"profile_id": "b3f1c2d4-5e6f-4a7b-8c9d-0e1f2a3b4c5d",
"engine": "qwen_custom_voice",
"instruct": "warm, slow, cinematic"
}' \
--output line.wavGames
Generate NPC dialogue on the fly, localize characters into new languages, or ship expressive voice lines without a studio.
Apps & agents
Give your app or AI agent a voice. Real-time narration, accessibility readouts, voice replies — all running on the user's machine.
Scripts & tools
Batch-generate audiobook chapters, automate podcast intros, or wire Alexander AI Voice into your Stream Deck. It's just a localhost URL.
Learn by watching
Walkthroughs from the community covering setup, voice cloning, and production workflows.

Free AI Voice Generator on Your PC (Clones Any Voice)
Kevin Stratvert

NEW Alexander AI Voice DESTROYS ElevenLabs?
Julian Goldie SEO

This Open-Source TTS App Sounds Scary Good (And It's Free)
Dave Swift

2026年最好的声音克隆工具?Alexander AI Voice完整测评:从下载到API调用,附速度对比
Tech指南
Get Started with Alexander AI Voice: Open-Source Alternative to ElevenLabs Tutorial
StinkyScrublet

Free AI Voice Generator (Clones Any Voice)
mikbes
Supported models
Pick the right model for every job — TTS, transcription, refinement. All models run locally on your hardware. Download once, use forever.
TTS Engines
Text → speech. Voice cloning, preset voices, and delivery control.
Qwen3-TTS
by AlibabaHigh-quality multilingual cloning with natural prosody. The only engine with delivery instructions — control tone, pace, and emotion with natural language.
Chatterbox
by Resemble AIProduction-grade voice cloning with the broadest language support. 23 languages with zero-shot cloning and emotion exaggeration control.
Chatterbox Turbo
by Resemble AILightweight and fast. Supports paralinguistic tags — embed [laugh], [sigh], [gasp] directly in your text for expressive speech.
LuxTTS
by ZipVoiceUltra-fast, CPU-friendly cloning at 48kHz. Exceeds 150x realtime on CPU with ~1GB VRAM. The fastest engine for quick iterations.
Qwen CustomVoice
by AlibabaNine premium preset speakers with natural-language style control. "Speak slowly with warmth", "authoritative and clear" — tone and pace adapt.
TADA
by Hume AISpeech-language model with text-acoustic dual alignment. Built for long-form — 700s+ coherent audio without drift. Multilingual at 3B.
Kokoro
by hexgrad · Apache 2.0Tiny 82M-parameter TTS that runs at CPU realtime with negligible VRAM. Pre-built voice styles — pick a voice, type, generate.
Transcription
Speech → text. Multi-language STT for dictation and captures.
Whisper
by OpenAIThe default. Mature multilingual ASR across a wide size range — pick Tiny for speed or Large for best accuracy.
Whisper Turbo
by OpenAIPruned Whisper Large v3. Near-best quality at roughly 8x the speed — the right default for real-time dictation.
Language Models
Transcript refinement, persona replies, and on-device reasoning.
Qwen3
by AlibabaPowers transcript cleanup, persona voice replies, and the voice I/O loop. Shares its runtime with the TTS/STT stack — one model cache, one GPU story.
Download Alexander AI Voice
Available for macOS, Windows, and Linux. No dependencies required.